


Section: Scientific Foundations
Co-modeling for HP-SoC design
The main research objective is to build a set of metamodels (application, hardware architecture, association, deployment and platform specific metamodels) to support a design flow for SoC design. We use a MDE (Model Driven Engineering) based approach.
Foundations
System-on-Chip Design
SoC (System-on-Chip) can be considered as a particular case of embedded systems. SoC design covers a lot of different viewpoints including the application modeling by the aggregation of functional components, the assembly of existing physical components, the verification and the simulation of the modeled system, and the synthesis of a complete end-product integrated into a single chip.
The model driven engineering is appropriate to deal with the multiple abstraction levels. Indeed, a model allows several viewpoints on information defined only once and the links or transformation rules between the abstraction levels permit the re-use of the concepts for a different purpose.
Model-driven engineering
Model Driven Engineering (MDE) [121] is now recognized as a good approach for dealing with System on Chip design issues such as the quick evolution of the architectures or always growing complexity. MDE relies on the model paradigm where a model represents an abstract view of the reality. The abstraction mechanism avoids dealing with details and eases reusability.
A common MDE development process is to start from a high level of abstraction and to go to a targeted model by flowing through intermediate levels of abstraction. Usually, high level models contain only domain specific concepts, while technological concepts are introduced smoothly in the intermediate levels. The targeted levels are used for different purposes: code generation, simulation, verification, or as inputs to produce other models, etc. The clear separation between the high level models and the technological models makes it easy to switch to a new technology while re-using the previous high level designs. Transformations allow to go from one model at a given abstraction level to another model at another level, and to keep the different models synchronized
In an MDE approach, a SoC designer can use the same language to design application and architecture. Indeed, MDE is based on proved standards: UML 2 [65] for modeling, the MOF (Meta Object Facilities [110] ) for metamodel expression and QVT [111] for transformation specifications. Some profiles, i.e. UML extensions, have been defined in order to express the specificities of a particular domain. In the context of embedded system, the MARTE profile in which we contribute follows the OMG standardization process.
Models of computation
We briefly present our reference models of computation that consist of the Array-OL language and the synchronous model. The former allows us to express the parallelism in applications while the latter favors the formal validation of the design.
Array-OL. The Array-OL language [90] , [91] , [83] , [81] is a mixed graphical-textual specification language dedicated to express multidimensional intensive signal processing applications. It focuses on expressing all the potential parallelism in the applications by providing concepts to express data-parallel access in multidimensional arrays by regular tilings. It is a single assignment first-order functional language whose data structures are multidimensional arrays with potentially cyclic access.
The synchronous model. The synchronous approach [79] proposes formal concepts that favor the trusted design of embedded real-time systems. Its basic assumption is that computation and communication are instantaneous (referred to as “synchrony hypothesis”). The execution of a system is seen through the chronology and simultaneity of observed events. This is a main difference from visions where the system execution is rather considered under its chronometric aspect (i.e., duration has a significant role). There are different synchronous languages with strong mathematical foundations. These languages are associated with tool-sets that have been successfully used in several critical domains, e.g. avionics, nuclear power plants.
In the context of the DaRT project, we consider declarative languages such as Lustre [85] and Signal [104] to model various refinements of Array-OL descriptions in order to deal with the control aspect as well as the temporal aspect present in target applications. The first aspect is typically addressed by using concepts such as mode automata, which are proposed as an extension mechanism in synchronous declarative languages. The second aspect is studied by considering temporal projections of array dimensions in synchronous languages based on clock notion. The resulting synchronous models are analyzable using the formal techniques and tools provided by the synchronous technology.
Contributions of the team
Our proposal is partially based upon the concepts of the “Y-chart” [97] . The MDE contributes to express the model transformations which correspond to successive refinements between the abstraction levels.
Metamodeling brings a set of tools which enable us to specify our application and hardware architecture models using UML tools, to reuse functional and physical IPs, to ensure refinements between abstraction levels via mapping rules, to initiate interoperability between the different abstraction levels used in a same codesign, and to ensure the opening to other tools, like verification tools, thought the use of standards.
The application and the hardware architecture are modeled separately using similar concepts inspired by Array-OL to express the parallelism. The placement and scheduling of the application on the hardware architecture is then expressed in an association model.
All the previously defined models, application, architecture and association, are platform independent and they conform to the MARTE OMG Profil ( figure 1 ). No component is associated with an execution, simulation or synthesis technology. Such an association targets a given technology (OpenMP, OpenCL, SystemC/PA, VHDL, etc.). Once all the components are associated with some IPs of the GasparLib library, the deployment is fully realized. This result can be transformed to further abstraction level models via some model transformations (figure 2 ).
The simulation results can lead to a refinement of the initial application, hardware architecture, association and deployment models. We propose a methodology to work with all these different models. The design steps are:
-
Separation of application and hardware architecture modeling.
-
Association with semi-automatic mapping and scheduling.
-
Selection of IPs from libraries for each element of application/architecture models, to achieve the deployment.
-
Automatic generation of the various platform specific simulation or execution models.
-
Automatic simulation or execution code generation with calls to the IPs.
-
Refinement at the highest level taking account of the simulation results.
High-level modeling in Gaspard2
In Gaspard2, models are described by using the recent OMG standard MARTE profile combined with a few native UML concepts and some extensions.
The new release of Gaspard2 uses different packages of MARTE for UML modeling. The Hardware Resource Model (HRM) concepts of MARTE enable to describe the hardware part of a system. The Repetitive Structure Modeling (RSM) concepts allow one to describe repetitive structures (DaRT team was the main contributor of this MARTE package definition). Finally, the Generic Component Modeling (GCM) concepts are used as the base for component modeling.
The above concepts are expressive enough to permit the modeling of different aspects of an embedded system:
functionality (or applicative part): the focus is mainly put on the expression of data dependencies between components in order to describe an algorithm. Here, the manipulated data are mainly multidimensional arrays. Furthermore, a form of reactive control can be described in modeled applications via the notion of execution modes. This last aspect is modeled with the help of some native UML notions in addition to MARTE.
hardware architecture: similar mechanisms are also used here to describe regular architectures in a compact way. Regular parallel computation units are more and more present in embedded systems, especially in SoCs. HRM is fully used to model these concepts. Some extensions are proposed for NoC design and FPGA specifications. The GPU have a particular memory hierarchy. In order to model the memory details, we extend the MARTE metamodel to describe low level characteristics of the memory.
association of functionality with hardware architecture: the main issues concern the allocation of the applicative part of a system onto the available computation resources, and the scheduling. Here also, the allocation model takes advantage of the repetitive and hierarchical representation offered by MARTE to enable the association at different granularity levels, in a factorized way.
In addition to the above usual design aspects, Gaspard2 also defines a notion of deployment specification (see Figure 1 ) in order to select compilable IPs from libraries, at this time models can produce codes. The corresponding package defines concepts that (i) enable to describe the relation between a MARTE representation of an elementary component (a box with ports) to a text-based code (and Intellectual Property - IP, or a function with arguments), and (ii) allow one to inform the Gaspard2 transformations of specific behaviors of each component (such as average execution time, power consumption...) in order to generate a high abstraction level simulation in adequacy with the real system. Recently this package was extended to design reconfigurable systems using dynamical deployment.
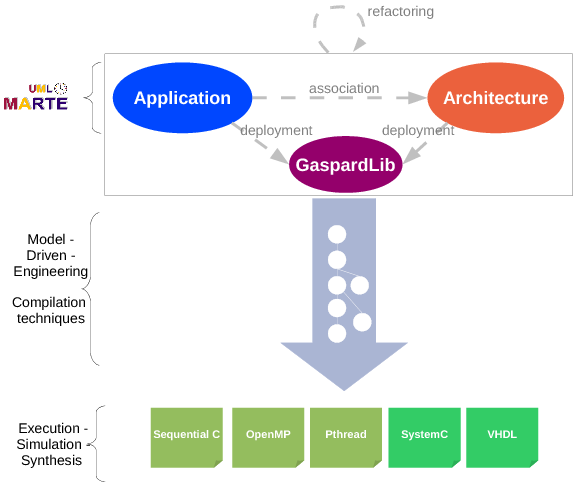
Intermediate concept modeling and transformations
Gaspard2 targets different technologies for various purposes: formal verification, high-performance computing, simulation and hardware synthesis (Figure 1 ). This is achieved via model transformations that relate intermediate representations towards the final target representations.
A metamodel for procedural language with OpenMP (OpenMP in Figure 1 ). It is inspired by the ANSI C and Fortran grammars and extended by OpenMP statements [68] . The aim of this metamodel is to use the same model to represent Fortran and C code. Thus, from an OpenMP model, it is possible to generate OpenMP/Fortran or OpenMP/C. The generated code includes parallelism directives and control loops to distribute task (IPs code) repetitions over processors [124] .
A VHDL metamodel (VHDL in Figure 1 ). It gathers the necessary concepts to describe hardware accelerators at the RTL (Register Transfer Level) level, which allows the hardware execution of applications. This metamodel introduces, e.g., the notions of clock and register in order to manipulate some of the usual hardware design concepts. It is precise enough to enable the generation of synthetizable HDL code [103] .
The two metamodels SystemC and Pthread was redefined to implement both a multi-thread execution model. These are described in the " New results" part.
Synchronous metamodel (Synchronous Equational). It was used to benefit of the verification tools of synchronous languages. It is not yet maintained in the new release of Gaspard2.
The transformation scheme. In order to target these metamodels, several transformations have been developed (Figure 2 ). MartePortInstance introduces into the MARTE metamodel the concept of PortInstance corresponding to an instance of port associated to a part. The ExplicitAllocation transformation explicits the association of each application part on the processing units, according to the association of other elements in the application hierarchy. The LinkTopologyTask transformation replaces the connectors between a component and an inner repeated part by a task managing the data (TilerTask). The scheduling of the application tasks is decomposed into three transformations, Synchronisation that associates, to each application component, a local graph of tasks corresponding to its parts; GlobalSynchronization that computes a global graph of tasks for the complete application from the local graphs of tasks; and Scheduling that schedules the tasks from the global graph. TilerMapping maps the TilerTasks onto processors. The management of the data in the memory is performed through two transformations. MemoryMapping maps the data into memory i.e. creates the variables and allocates address spaces. AddressComputation computes addresses for each variable. Finally, some transformations are dedicated to targets: Functional introduces the concepts relative to procedural languages. pThread transforms MARTE elementary tasks into threads and the connectors into buffers. SystemC traduces the MARTE architecture into concepts of the SystemC language.
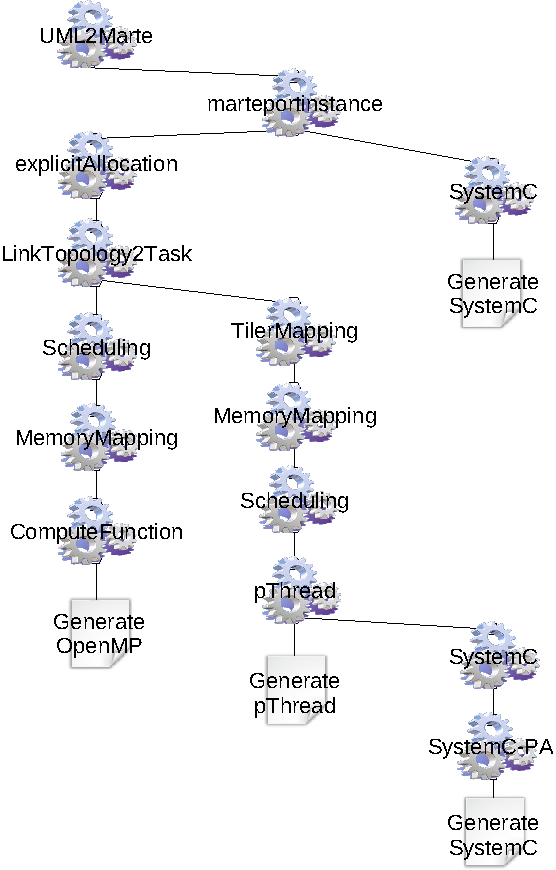
An operational semantics for RSM
The Repetitive Structure Modeling (RSM) package of the UML MARTE profile is used to describe repetitive computations and topologies (e.g., data-parallel algorithms, grid of processing units) in an embedded system. In Gaspard2, the concepts provided by this package are of prime importance for the specification of data-intensive applications. A formal semantics [82] has been previously defined for the Array-OL language, which is the basis for the definition of RSM. We proposed an new formal semantics for RSM, which is operational unlike [82] . Execution semantic descriptions are rarely taken into account in the definition of UML profiles. This raises several serious correctness issues about the manipulation of models defined with these profiles. The aim of our new semantics [100] is to answer this demand by proposing a help for understanding the behavior and execution of models specified with RSM concepts in UML MARTE.
Clock-based modeling of embedded system behavior
The concepts defined in the RSM package of MARTE allow one to suitably describe the data intensive algorithms [70] [69] . In order to add more details about the system functional behavior, logical clocks are associated with components to describe the expected rates at which data should be processed. The Time sub-profile of MARTE is used to model this rate information. It offers a rich expressivity for describing both logical and physical time aspects [74] . The rate constraints are expressed using the CCSL package of MARTE in the form of clock constraints. We refer to this clock constraints as functional clock properties.
The physical resources that implement the data intensive algorithms are specified in MARTE. For each resource, hardware IPs are deployed in order to refine the models towards a specific technology. At this level, we extract information concerning the processors speed represented by its frequency. We synthesize new clocks that represent the periods of the clock cycles for each processor involved in the execution. All clocks are related to an ideal clock. The occurrence of the instants of the ideal clock are fast enough to capture any instant of the processors clocks. We refer to these clock specifications as physical clock properties.
Since application functionality and hardware architecture are modeled independently in Gaspard2, the allocation phase bridges these two different views in order to map functionality on their associated physical resources. In terms of clocks, this allocation is expressed as the mapping of functional clock properties onto physical clock properties, according to a particular mapping algorithm. The result of such allocation is a new set of clocks reflecting the simulation of the temporal behavior of the system during execution. We refer to these clock description as simulation clock properties. They are usable for a very relevant system analysis.
High-level modeling and exploration of non functional properties
We have proposed an approach for high-level modeling and exploration of non functional properties. Our work proposed a Model Driven Engineering (MDE)-based approach to integrate non functional requirements for systems on chip and defined metamodels that allow the integration of external optimization tools in the Gaspard2 environment. The designer creates the application and architecture models at a high level. The designer should then take the decision to allocate application functions on hardware components. This decision depends essentially on the non functional properties of both of the software and hardware components. For this reason, it is necessary to express these requirements. The proposed methodology uses models enriched with non-functional properties to drive the optimization of resource allocation.
HPF towards Marte
Concerning the power of expression of the MARTE RSM subprofile that we have defined, we have studied the data and computation distribution capabilities. We have proved that the MARTE «distribute» stereotype is at least as expressive as the well known High Performance Fortran data distribution. The proof is constructive: starting from an ALIGN and a DISTRIBUTE HFP directive, we build a MARTE «distribute».
MARTE extensions for reconfigurable based systems
Reconfigurable FPGA based Systems-on-Chip (SoC) architectures are increasingly becoming the preferred solution for implementing modern embedded systems. However due to the tremendous amount of hardware resources available in these systems, new design methodologies and tools are required to reduce their design complexity.
In previous work, we provided an initial contribution to the modeling of these systems by extending MARTE profile to incorporate significant design criteria such as power consumption.
In its current version, MARTE lacks dynamic reconfiguration concepts. Even these later are necessary to model and implement rapid prototypes for complex systems.
Our objective is to define all necessary concepts for dynamic reconfiguration issues regarding configuration latency, resources number, etc. Afterwards, these concepts will be integrated to MARTE to obtain an extended and complete profile, which can be called Reconfigurable MARTE (RecoMARTE).
Our current proposals permit us to model fine grain reconfigurable FPGA architectures with an initial extension of the MARTE profile to model Dynamic Reconfiguration at a high-level description.
Since a controller is essential for managing a dynamically reconfigurable region, we modeled a state machine at high abstraction levels using UML state machine diagrams. This state machine is responsible for switching between the available configurations.
As a future work, we will analyze the reconfigurable design flow of Xilinx from the design partitioning to the bitstream generation stage. It is a starting point for understanding how to generate configuration files. Then, we will extract relevant data to define our own design flow.
Traceability
We use the transformation mechanism to assist a tester in the mutation analysis process dedicated to model transformations. The mutation analysis aims to qualify a test model set. More precisely, errors are voluntary injected in transformation and the ability of the test models set to highlight these errors is analyzed. If the number of highlighted errors, i.e. if the test model set is not enough qualified, new models have to be added in order to raise the set quality [108] . Our approach relies on the hypothesis that it is easier to modify an existing model than to create a new one from scratch. The local trace, coupled to a mutation matrix, helps the tester to identify adequate test models and their relevant parts to modify in order to improve the test data set. We propose a semi-automation approach that can automatically generate new test model in some cases and efficiently assist the testers in others cases [77] .
Transformation migration after metamodel evolution
Metamodels evolve because of several reasons such as design refinement and software requirement changes. When this happens, transformations defined in terms of those metamodels might become inconsistent and migration would be necessary. Due to the lack of methodology support, transformation migration is mostly ad hoc and manually performed. Besides, the growing complexity and size of transformations make this task difficult and error prone. We started works in this domain area. More specifically, on the one hand, we specify transformation consistency by defining the relationship between transformation and metamodels, we called it domain conformance. On the other hand, we propose a transformation migration process which describes the set of tasks that should be completed in order to re-establish consistency after metamodel evolution [107] , [116] .
Model transformation towards SystemC-PA
The buffered strategy developed for the transformation chain towards pThread has been kept to simulate the behavior of the application for the SystemC-PA simulation target. Mapped tasks are associated to threads themselves run on SystemC processing modules. Most of the thread contents (concepts, transformation and code generator) were reused and coupled with the SystemC contents dedicated to the architecture. A new model transformation has been developed to map the threads related to the application to the SystemC elements related to the architecture. The data accesses in the new SystemC-PA target are triggered off when the buffers (Pthread mechanisms) are requested. Those accesses are forwarded to the architecture through the TLM2 communication channels of the processors running the thread. The resulting transformation chain is available in the on-line Gaspard version (http://www.gaspard2.org ).
Gaspard2 for avionic hybrid test platform design
The emergence and the maturity of FPGA circuits for distributed and reconfigurable architectures offer the opportunity to explore real time problems in the field of avionic systems. FPGA becomes de facto a major processing element as same as general CPUs. As of now, the FPGA is widely used in the field of I/O component in order to connect the real equipment with the CPU host. Among the main features mapped into the FPGA in the original architecture, we quote the fast serial link and RAM IPs (Intellectual property) which are needed to ensure communication between CPU and FPGA. Additionally, the Base Time IP is needed for the global system synchronization. This minimal configuration based on FPGA can be duplicated several times and connected together to build bigger test system or a complete simulator. Eurocopter expectation for the above-described architecture is to prototype some models which can be eligible and relocated in the FPGA. The objective is to increase the performances of these models and to reduce the communication latencies by the means of embedding the different parts in the same chip. To do so, we studied in this first year a real avionic test loop in order to extract the complex models that will be implemented in the FPGA. Different hardware model configurations have been explored to reach an optimal well-balanced global system using the ML403 Virtex-4 Xilinx board. Different tradeoffs in terms of performance and resource occupation in the FPGA are obtained. Later, these results will be used for dynamically adapt the system functioning according to the available resources and performance requirements.
As a second part, we used the MARTE profile to represent an hybrid system (CPU/FPGA).In the MARTE specification, an application is a set of tasks connected through ports. Tasks are considered as mathematical functions reading data from their input ports and writing data on their output ports. This specification has been used to model the avionic test loop. In addition, MARTE allows describing the hardware architecture in a structural way. Typical components such as HwProcessor, HwFPGA and HwRAM can be specified with their non-functional properties. We used this subset of MARTE in order to represent an hybrid multiprocessor architecture. The main component of this architecture is composed of the Xeon-X3370 processor (multicore CPU) and the Virtex-4 Xilinx FPGA. Furthermore, MARTE provides the Allocate concept as well as the concept specially crafted for repetitive structures Distribute. This latter concept gives a way to express regular distribution of tasks onto a set of processors or FPGA resources. The mapping step relies on two types of distribution (timeScheduling and spatialDistibution) depending on the target hardware platform (CPU/FPGA). The different models of our avionic test loop can be mapped onto the host multicore processor, the embedded processor (Microblaze) or the hardware resources in the FPGA.